使用sk-learn解决二分类问题
sk-learn是一个python的机器学习工具库,最早基于scipy发展而来,可以与pandas、matplotlib、numpy等库无缝结合。本文主要介绍上手用sk-learn做二分类预测的方法和一些使用过程中的心得。按机器学习的步骤,我把文章分为三个部分:数据集准备、模型训练、模型检验。
数据集准备
数据来源
首先要明确我们要解决的是什么问题,输入输出分别是什么。标注数据可以来源于生产环境中的真实数据,也可以在网上下载的一些数据,比较常见的有iris,mnist,还有一些竞赛数据,处于学习目的都可以拉下来用。为了简单,我们假设数据随机生成,每个数据有两个feature(两维),用n行2列的数组表示。
这里要插一句:sk-learn的输入支持多种格式,无论是数组还是np.arrays都可以
|
1 2 |
x = np.random.rand(100,2) # 生成100组数据,每组数据2个feature (称为fa, fb) y = np.array([[int(tk[0]>tk[1])] for tk in x]) # 输出: fa是否大于fb = =|| |
数据组成
二分类问题中正负样本的比例是一个仁者见仁智者见智的问题,通常来说使正负样本数相同、或与真实数据比例保持一致就可以。但是如果某一方数据较少,或者特征较弱,则可以适当增加比例。
但是如果某一方数据极少,则是另一个问题了(class imbalance),可以通过采样方法平衡,甚至通过一些半监督方法去搞 (出门右转搜索TSVM或者一些generate model,我暂时还不会)
标准化和归一化
标准化是一种将所有数据无量纲化,映射到相同的区间内。通常方法是将原数值减去平均值后除以标准差。标准化后的数据都聚集在0附近,方差为1(z-score)。sk-learn提供了标准化函数:
|
1 2 |
from sklearn import preprocessing x_scaled = preprocessing.scale(x) # z-score |
归一化作用是将数值映射到[0,1]区间内,公式是 归一值=(原值-min)/(max-min) 。sk-learn也提供了归一化函数:
|
1 |
x_normalized = preprocessing.normalize(x) # min-max |
通常需要进行梯度优化的机器学习算法需要标准化和归一化,如LR、nn等,决策树之类的不用做(是基于信息增益的)。
shuffle以及训练集、测试集划分
shuffle是指打乱数据的原有顺序,不多说了。
为了验证模型效果,通常会使用70~80%的数据用来训练模型,剩下的数据用于验证原有模型,这样可以了解模型的泛化能力。当然也可以使用k-fold等方法做多轮交叉验证。
下面这个函数提供了shuffle和切分的功能:
|
1 2 |
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2) # test_size指测试集占总数据的比例 |
模型训练
在数据准备阶段我们已经得到了x_train, x_test, y_train, t_test,接下来这部分我们需要用x_train和y_train来训练我们的模型。
sk-learn提供了很多种易(bu)于(yong)上(can)手(shu)的机器学习类可以使用,这些类都实现了fit()、predict()等方法,用起来非常简单,也非常容易构建多种不同方法的机器学习模型和混合模型。
例子 — Logistic回归
|
1 2 3 |
from sklearn.linear_model import LogisticRegression clf = LogisticRegression() # 直接 clf = 引入的类() 就ok clf.fit(x_train, y_train) # 通用的fit方法接口 |
其他常用的机器学习类
|
1 2 3 4 5 6 |
from sklearn.linear_model import LogisticRegression, Ridge, LinearRegression, ... # 各种线性模型 from sklearn import tree # 决策树模型 from sklearn.ensemble import RandomForestClassifier # 随机森林 from sklearn.neighbors import KNeighborsClassifier # KNN from sklearn.naive_bayes import GaussianNB # 朴素贝叶斯 ...... |
其实在模型建立的时候是可以设置若干参数的,直接 print clf 可以看到模型的默认参数,我们可以对其进行设置。具体文档请看官方文档。
模型检验
预测结果检验
模型训练结束之后我们要使用x_test, y_test来检验我们的模型。模型好坏有两个直接指标:准确率和召回率,这个应该不用说了吧。在这两者之上,f1-score是一种较好衡量二分类模型的一种指标,兼顾了准确率和召回率,详见百度百科。sklearn.metric库中提供了一些很好用的工具,会给出这些指标:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
from sklearn.metrics import classification_report y_pred = clf.predict(x_test) print classification_report(y_test, y_pred,target_names=['good', 'bad']) ''' 一个输出的例子 precision recall f1-score support normal 0.82 0.92 0.87 12024 cheat 0.85 0.68 0.76 7600 avg / total 0.83 0.83 0.83 19624 ''' |
Precision Recall Curve (PR)
在我们的期望中,准确率和召回率自然是越高越好,都高更好。但是通常情况下两者呈此消彼长之势。通过PRC图可以看出模型效果(我通常拿来做几个模型之间的比较,画到一个图里,越高的、越平滑的曲线越好。
|
1 2 3 4 5 6 7 |
precision, recal, thresholds = precision_recall_curve(y_test, clf.predict(x_test)) # 画图部分 import matplotlib.pylab as pylab ax = pylab.subplot(2, 1, 2) ax.plot(recall, precision) ax.set_ylim([0.0, 1.0]) pylab.show() |
Receiver Operator Characteristic Curve (ROC)
ROC曲线是一种评价二分类分类器效果的曲线,他使用FP_Rate(false positive)和TP_Rate(True Positive)值进行作图
|
1 |
fpr, tpr, thresholds = roc_curve(y_test, flt.predict(x_test) |
关于PR和ROC的关系,这里有一篇论文,The Relationship Between Precision-Recall and ROC Curves(不想研究细节的就可以跳过了)。通常ROC曲线越凸向左上角越好,PR曲线越高越好。
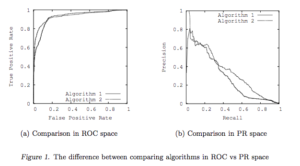
此外还有很多评价方法,gini、AUC等,在此不详细说明了。有个博客写的挺好的推荐一下~
模型调优
搞机器学习最恶心的两件事就是洗数据和调参数了……通常我们训练出的模型可能表现还可以,但是参数都是默认的,肯定有地方可以压榨。
sk-learn提供了两种参数优化的方法
- GridSearchCV,网格搜索,一个网格其实就是一个参数的所有取值,搜索所有参数的所有组合找到最优组合。
- RandomizedSearchCV,随机采样搜索,根据某种采样方法随机找到一些参数组合。
使用GridSearchCV的时候,比如要寻找比较好的C值(LR),那么代码如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from sklearn.model_selection import GridSearchCV C = [1, 10, 100] # 网格内要搜索的参数列表 clf = LogisticRegression() gridSearch = GridSearchCV(estimator=clf, param_grid={'C': C}) gridSearch.fit(x, y) print gridSearch print gridSearch.best_score_ print gridSearch.best_estimator_.C ''' GridSearchCV(cv=None, error_score='raise', estimator=LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False), fit_params=None, iid=True, n_jobs=1, param_grid={'C': [1, 10, 100]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0) 0.804572045904 1 ''' |
使用RandomizedSearchCV如下
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from scipy.stats import uniform # uniform是均匀分布,也可以用正态(norm),beta等 from sklearn.model_selection import RandomizedSearchCV clf = LogisticRegression() randSearch = RandomizedSearchCV(estimator=clf, param_distributions={'C': uniform()}, n_iter=10) randSearch.fit(x, y) print randSearch print randSearch.best_score_ print randSearch.best_estimator_.C ''' RandomizedSearchCV(cv=None, error_score='raise', estimator=LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True, intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1, penalty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False), fit_params=None, iid=True, n_iter=10, n_jobs=1, param_distributions={'C': <scipy.stats._distn_infrastructure.rv_frozen object at 0x10164d0d0>}, pre_dispatch='2*n_jobs', random_state=None, refit=True, return_train_score='warn', scoring=None, verbose=0) 0.804592429524 0.750632384408 ''' |
混合模型
每个模型效果不一样,一般不会有通吃的模型,可能有的准确率高一些,有的召回率高一些。这个时候可以训练多个模型,把结果揉在一起,根据不同的特性输出不同的结果,可以使效果得到提升。